
I have been focusing a lot of attention on performance tuning AX over the last year. The company I work for has now been live on AX 2012 R2 for about a year and a half and we’ve spent a lot of effort tuning indexes and re-writing code and processes to speed up our system. Spending so much time thinking about performance has caused me to change the way I write and fix code so I figured I would share.
Outside of making sure you have good indexes for your tables, the biggest offender I’ve found for slow processes is unnecessary database calls. I see it and have been guilty of writing it in code all the time. You have a process that loops through records, evaluates some conditions, grabs related data if necessary and then performs some action. The offender in this scenario is “grabs related date if necessary”.
It is really easy to write a basic query to start off with and then, in the middle of your process, grab more data. AX 2012 makes it easy for you with Table::find() methods and by having the CreateNavigationPropertyMethods property on a table relation. This allows a developer to grab a related table from an existing table buffer using a method call that matches the relation (e.g CustTable.DirPartyTable_FK()). While this is incredibly useful, the danger with this approach is that it adds another database call to the process.
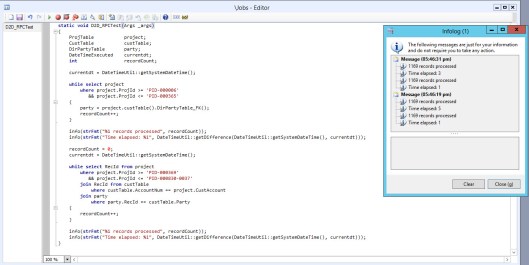
Examine the job above. I have 2 while select statements that loop through the same number of records. I have used different ranges so I could show times for cached and non-cached results. The first loop grabs the project records and then during processing makes 2 more database calls to get the CustTable and then the DirPartyTable. The second loop uses joins and a field list to minimize both the amount of data returned and the number of database calls.
I ran this process twice. The infolog shows that the first loop took 5 seconds to run and the second loop took 1 second to run. The second time I ran this process the first loop fell to 3 seconds because of database caching. This means that the first loop takes 5 times longer to run when it’s calling the database and 3 times longer when its reading from the cache (a precision of seconds is probably minimizing this difference). 5 seconds doesn’t seem like a long time to process over 1100 records but there are a few things to consider. This process isn’t doing anything but grabbing the records and this job was run in a stand-alone development environment. The client, AOS and database are all on the same server and there is no one else using it except for me. Imagine how much longer this could be if there were lots of users running processes in the system or if the components were separate and the network happened to be slow.
Each database call can add up to 2 remote procedure calls depending on where the code is running. In this instance, my job is running on the client so the number of RPC’s is twice the number of database calls (1 from client to AOS and 1 from AOS to database). The first loop has 2 RPCs for the while select, and then 2 (number of calls) X 2 (client and server) X 1169 (number of records) for a total of 4,678 RPCs and 2,339 database calls. The second loop has 2 RPCs and 1 database call and the potential to give you just as much data as the first loop. That’s a pretty crazy difference!
I now write a lot more X++ pseudo-SQL with joins when writing new code and changing existing processes. The amount of time that can be saved during runtime far outweighs the extra time it takes to plan out your processes to grab all of the data that is needed the first time.
